Бухгалтер получает 40 документов в день. Счета-фактуры, акты, накладные, договоры. Половина - PDF из почты. Треть - сканы с печатями. Остальное - фото на телефон, рукописные правки, Excel с вложенными таблицами. Каждый нужно открыть, прочитать, перенести данные в учетную систему. Вручную.
Мы занимаемся этой задачей три года. Перепробовали десятки подходов. Некоторые казались идеальными в демо и разваливались на реальных документах. Вот что осталось в production к 2026 году.
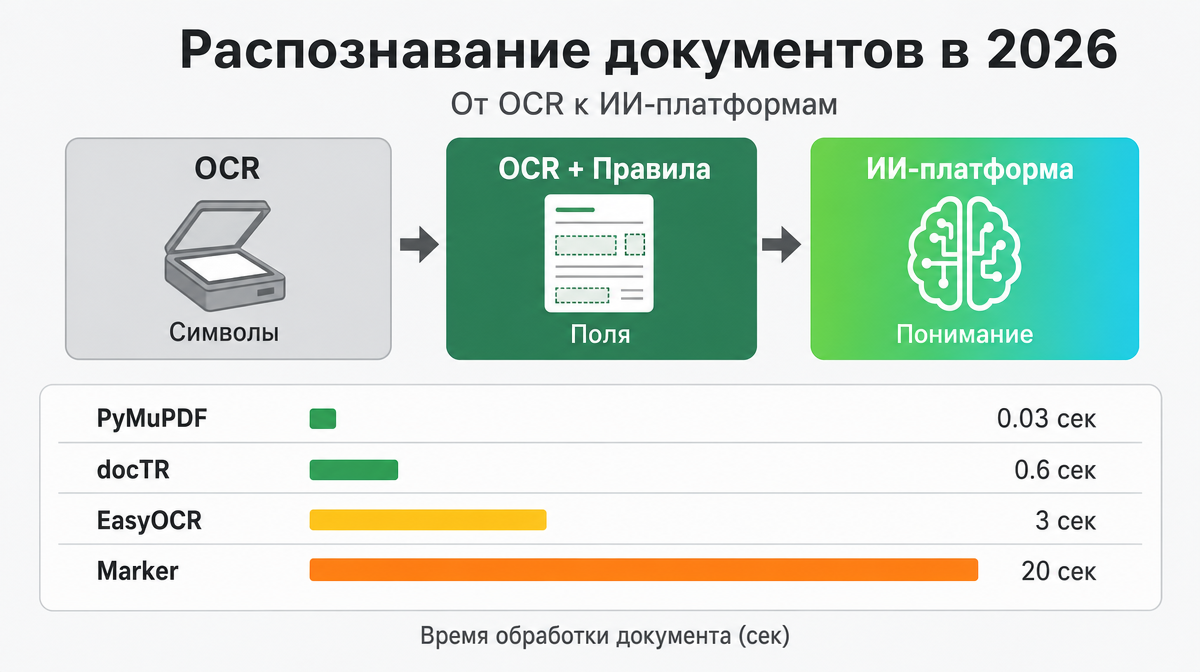
Три поколения распознавания документов
Классический OCR - Tesseract, ABBYY FineReader, PaddleOCR - распознает символы на изображении и возвращает текст. На чистых сканах с печатным шрифтом работает нормально. На рукописном тексте, таблицах, документах с печатями - нет.
Следующий шаг - OCR с правилами. К распознаванию добавляются шаблоны: "в этом месте документа стоит ИНН", "после слова Итого - сумма". Это работает ровно до момента, когда приходит документ от нового контрагента с другой структурой. А он приходит всегда.
Третье поколение - ИИ-платформы. Нейросети не ищут текст по координатам. Они понимают документ целиком: "это счет-фактура, вот поставщик, вот сумма, вот НДС". Не нужно настраивать шаблон на каждый формат. На этом принципе построена наша платформа.
OCR распознавание текста - что реально показывают движки
Мы гоняли несколько OCR-движков на реальных клиентских документах. Разница в скорости - в сотни раз.
| Движок | Скорость (1 страница) | Когда использовать |
|---|---|---|
| PyMuPDF | 0.03 сек | Цифровые PDF - текст уже есть в файле, OCR не нужен |
| docTR | 0.6 сек | Сканы и фото - быстрый, точный, хорошо держит русский |
| EasyOCR | 2-5 сек | Сложные алфавиты - арабский, хинди, смешанные скрипты |
| Marker | 19-24 сек | Документы со сложными таблицами и вложенной структурой |
"Лучшего" движка нет. 80% документов в типичной компании - цифровые PDF. PyMuPDF обрабатывает их за 0.03 секунды, и OCR тут вообще не нужен. Оставшиеся 20% - сканы и фото - идут через docTR или Marker, в зависимости от сложности документа.
Платформа выбирает движок автоматически. Загружаете файл - система определяет тип и маршрутизирует.
Распознавание рукописного текста - почему это сложнее
Рукописный текст - отдельная история. Классический OCR (Tesseract, PaddleOCR) на рукописных правках и резолюциях теряет больше половины символов. Для работы это непригодно.
Нейросетевые модели (Gemini Flash, GPT-5.4, GigaChat Vision, YandexGPT) подходят к задаче иначе. Они не разбирают отдельные символы - они "читают" страницу целиком, как человек. В нашей практике разница с классическим OCR - в разы, не в проценты.
Конкретный пример: договор с рукописными правками поверх печатного текста. Классический OCR видит кашу из наложенных символов. VLM-модель понимает, что зачеркнутый текст заменен рукописной вставкой, и извлекает финальную версию.
Есть компромисс. VLM-модели не возвращают координаты текста на странице. Если нужно знать не только "что написано", но и "где именно на странице" - используем гибрид: VLM для текста, классический OCR для координат.
ИИ-платформа vs классический OCR - в чем разница на практике
Классический OCR возвращает текст. Строки символов. Дальше вы сами разбираетесь, где номер счета, а где сумма.
ИИ-платформа возвращает структурированные данные. Загружаете счет-фактуру - на выходе поля: поставщик, покупатель, номер, дата, позиции, суммы, НДС.
Вот как это выглядит на реальной задаче. Страховая компания обрабатывает 8,000+ прайс-листов клиник ежемесячно. Каждый прайс - свой формат: Excel, PDF, скан. В одном прайсе 1,372 строки медицинских услуг.
С классическим OCR: текст извлечен, дальше ручная работа - парсить таблицы, маппить на внутреннюю номенклатуру (10,000+ кодов). Дни работы.
С нашей платформой: загрузка файла, 70 секунд, 4,356 услуг извлечены и сопоставлены с номенклатурой. 99.8% покрытие. 17 несопоставленных позиций оказались не медицинскими услугами - в прайс попали "Принтер", "Стол" и другая офисная техника.
Обработка сканов документов - три ловушки
Сканы - самый проблемный тип входных данных.
Смешанные PDF. Документ на 20 страниц. Первые 15 - цифровой текст. Последние 5 - сканы приложений с подписями. Большинство систем обрабатывают первые 15 страниц за секунду и молча теряют данные с последних пяти. Без предупреждения, без ошибки в логе.
Мы проверяем каждую страницу отдельно: средняя длина текста, наличие изображений, соотношение картинок к тексту. Смешанный PDF детектируется и обрабатывается постранично - разные страницы идут через разные движки.
Намеренно плохие сканы. В судебных экспертизах ответчик не заинтересован в том, чтобы документы было легко анализировать. КС-2 приходят нечеткими сканами, в разных форматах, с рукописными правками поверх печатного текста. Мы обрабатывали тысячи таких позиций для аудиторской компании, проводившей экспертизу жилого комплекса. Данные шли в суд.
Excel через OCR. Некоторые системы рендерят xlsx в картинку и распознают через OCR. Это в 250 раз медленнее прямого извлечения - 144 секунды вместо 0.09. И генерирует артефакты. Для структурированных форматов мы используем прямое извлечение. OCR - только для сканов.
Как выбрать решение для распознавания документов
Если у вас меньше 50 документов в день одного типа - классического OCR с ручной доработкой хватит. Серьезно. Не нужно покупать платформу ради 20 накладных в день.
Если документов больше, форматы разные, контрагенты каждый месяц новые - тогда нужна ИИ-платформа. Четыре вопроса, которые стоит задать вендору на демо:
Работает ли система без шаблонов? Если на каждый новый формат нужно настраивать правила - это второе поколение, не третье. Вы будете вечно догонять.
Что происходит со смешанными PDF? Загрузите документ с цифровыми и сканированными страницами. Если часть данных пропала - у системы нет постраничной маршрутизации.
Где обрабатываются данные? Финансовые документы, договоры, персональные данные - это не должно уходить на внешние серверы. Приватное развертывание - не опция, а требование.
Какая реальная скорость? Не на демо-файле в 1 страницу. На вашем документе в 50 страниц со смешанным содержимым, таблицами и подписями.
Попробовать
Загрузите свой документ - покажем результат на ваших данных. PDF, Excel, сканы, фотографии. В том числе с рукописными правками.
Подробнее о платформе: AI Data Extractor - извлечение данных из документов.
AI Data Extractor - распознавание документов и извлечение данных. OCR, нейросети, обработка сканов. Работает без шаблонов, в закрытом контуре.